
それでは、今回は「【Jupyter Notebook】Matplotlibで2次元グラフを描こう【その3:ヒストグラム基礎編】」の続編として【その4:ヒストグラム応用編】として複数のグループの値を一つのヒストグラムに表示する方法と、近似曲線をヒストグラムに追加する方法を説明します。
Matplotlibの初心者の方は、Matplotlibで2次元グラフを描こう【その3:ヒストグラム基礎編】とこの記事にあるリンク先の記事に目を通していただけると、理解が早くできると思います。
複数のグループの値をヒストグラムに表示する。 histogram_05
histogram_05
それでは、有名なsklearnのトイデータセットであるアヤメの花のサイズに関するデータセットを使って、ヒストグラムに複数のグループを表示する方法を説明していきます。複数グループの表示方法は、半透明にして重ねる方法、横に並べる方法、上に積み上げる方法の3つの方法を説明します。
sklearnのトイデータセットについては、ぼくの別記事、Python sklearnのデータセット【datasets】について(その1:トイデータセット)を参照してください。
まずは、アヤメの花のサイズに関するデータセットを使って、花の萼片(がくへん)(sepal)の長さに関するヒストグラムを作成します。取り敢えずは、アヤメの品種に関しては区別せず、150個のサンプル全てに関するヒストグラムの描写を復習を兼ねて行います。
 histgram_a_01
histgram_a_01
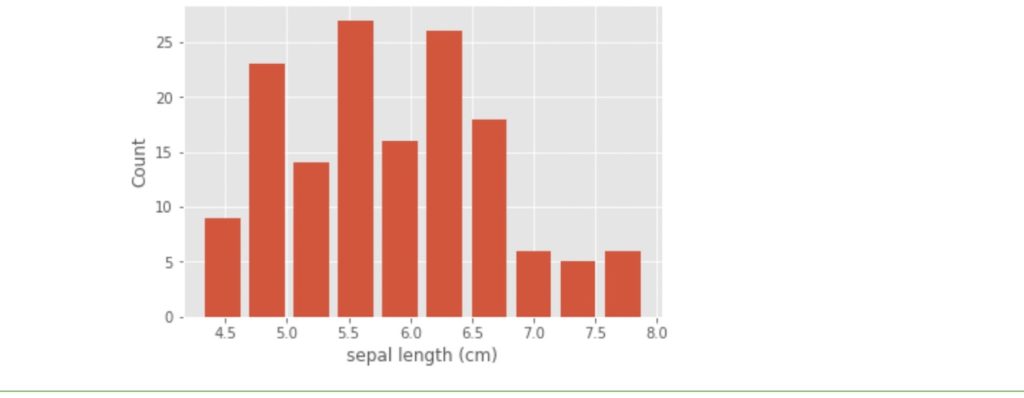 histgram_a_02
histgram_a_02
それでは簡単に上記のコードを説明します。基本的にはヒストグラムの基礎編で説明した内容を理解されていれば、問題ないはずですが、一つだけ、pandasというライブラリーからDataFrameという機能を新しく使っています。このpandasについては、まだぼくのブログでは解説していないので、ネットで調べていただきたいのですが、(すいません。)この機能は、pandasというよりは、Pythonの機能としてかなり重要ですので、ゆくゆくは記事にしたいと思っています。これでは、以下でここのコードを解説します。
これ以降は、ヒストグラムの基礎編で解説した通りに単純にヒストグラムを描いているだけです。いかがでしょうか。それとライン15の縦線は、カーソルが写っているだけですので、無視して下さい。(ごめんなさい。)
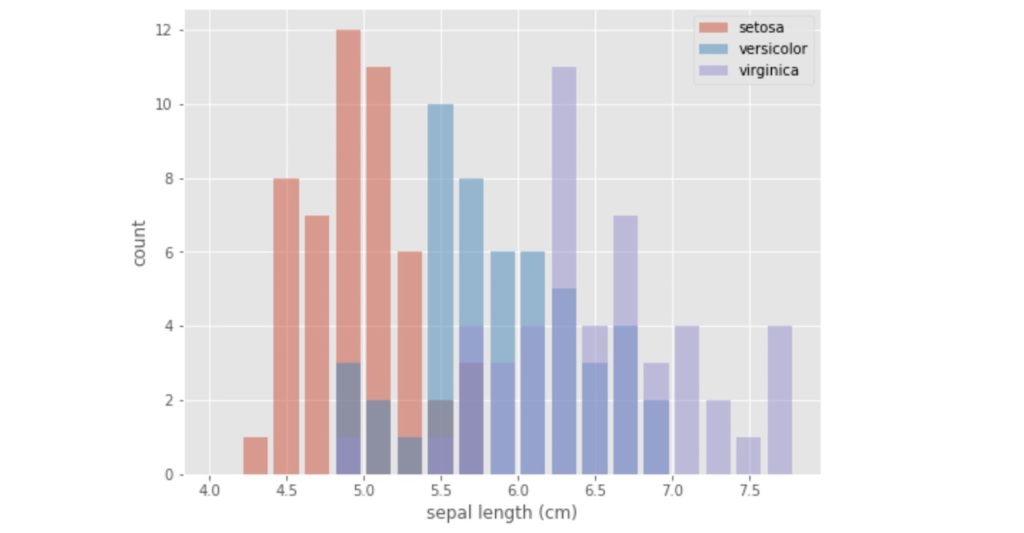
複数のグループの値を重ねて表示するそれでは、本題の複数のグループの値を重ねて表示する方法の説明に入ります。
 histgram_a_03
histgram_a_03
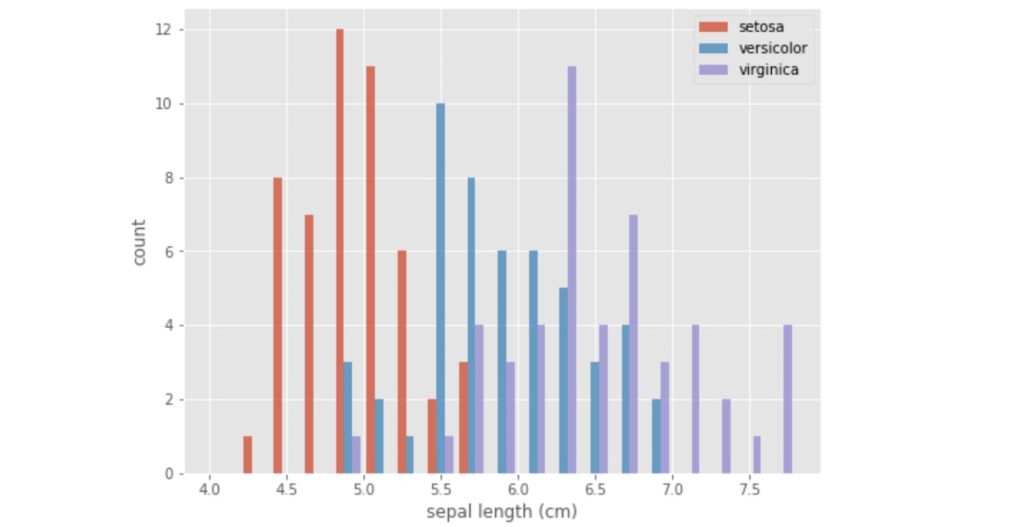
 histgram_a_04
histgram_a_04
コードの解説は以下の通りです。
複数のグループの値を横に並べて表示する方法をご説明いたします。
 histogram_a_05
histogram_a_05
 histgram_a_06
histgram_a_06
それでは、コードの解説を行います。
それでは複数のグループの値を上に積み上げて表示する方法をご説明いたします。
 histogram_a_07
histogram_a_07
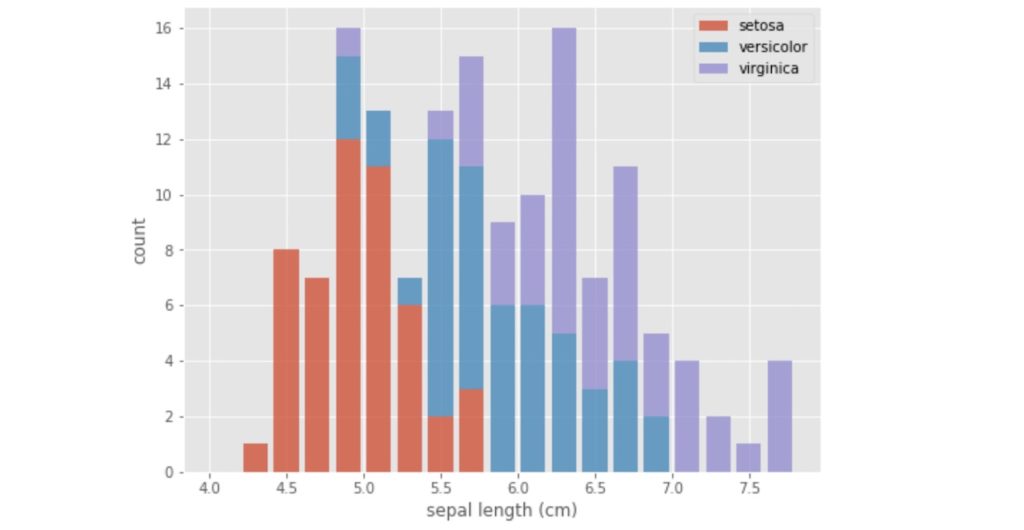 histgram_a_08
histgram_a_08
 histogram_04
histogram_04
 histgram_a_09
histgram_a_09
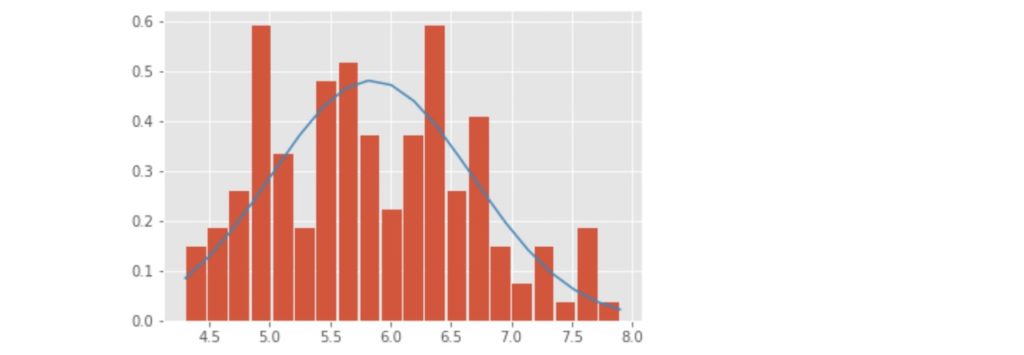 histgram_a_10
histgram_a_10
それでは近似曲線に関するコードを解説していきます。
 histogram_02
histogram_02
その1から今回のその4とMatplotlibを使っての2次元グラフの描写方法を説明してきました。一応このシリーズはこれで終了にします。今後はpandasに関する説明を予定しています。
それでは、最後までお付き合いありがとうございました。さようなら。












